



.svg)
Productionizing LLMs



.svg)


Introduction
In recent years, large language models (LLMs) have exploded in popularity. These text generation models, most commonly based on the transformer design laid out in Attention is all You Need, have shown promising results. Abstractions built around LLMs have leveraged their strengths and reinforced their weaknesses to create real, practical applications. Here at Enable Medicine, we’ve applied these tools and abstractions to build a variety of platform-specific features such as cell labelling given biomarker expression levels, semantic search, and an assistant chat bot that allows users to ask questions and execute actions on our platform.
Embeddings
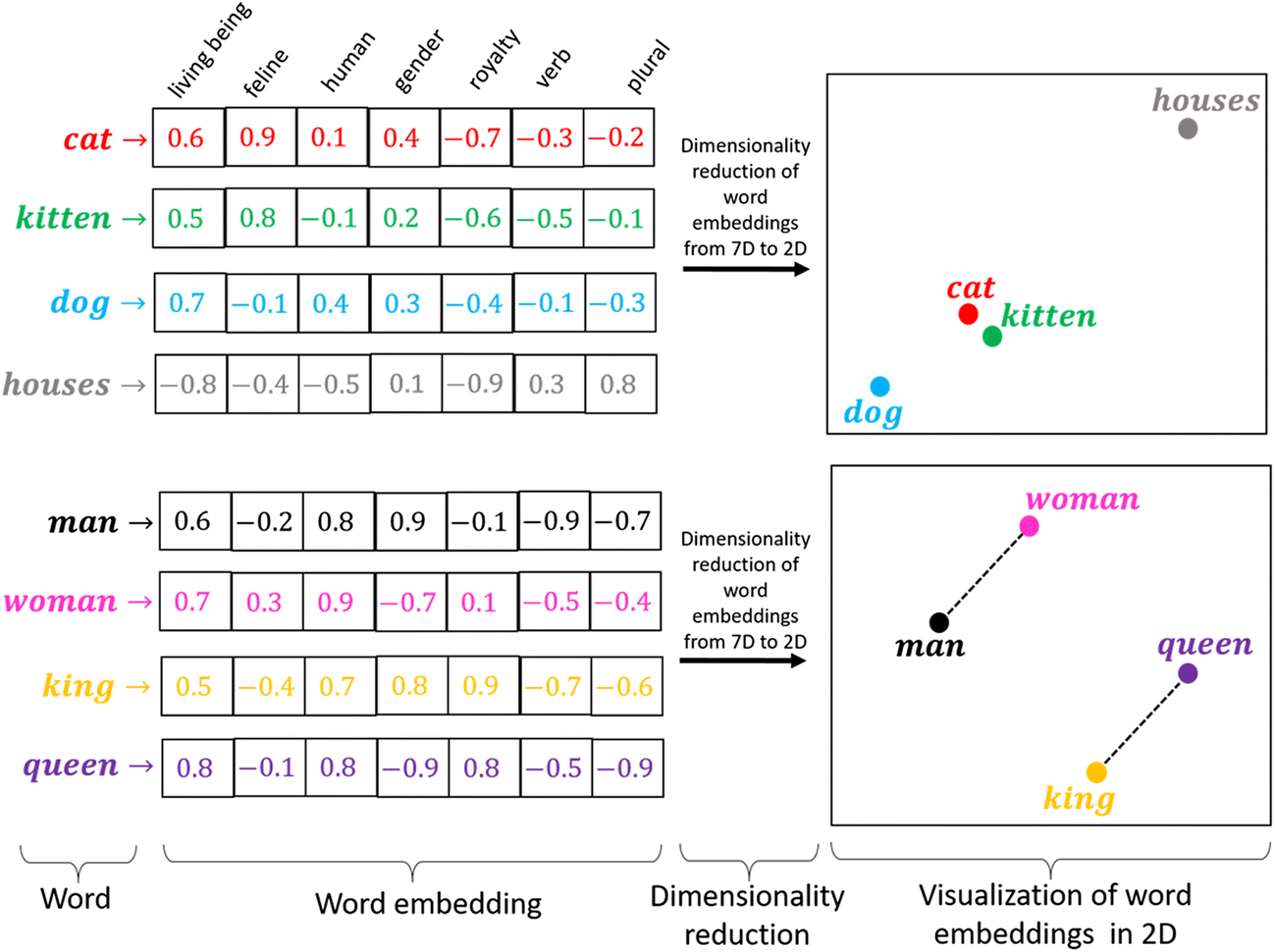
One of the fundamental concepts in LLM applications is embeddings. An embedding is a vector representation of a data point. In the context of language models, it represents text. The most useful property of embeddings is that texts with similar meanings will have similar embedding vectors. This property enables semantic search. When searching for entities, we can compare the meaning of the query to the meaning of the entities.
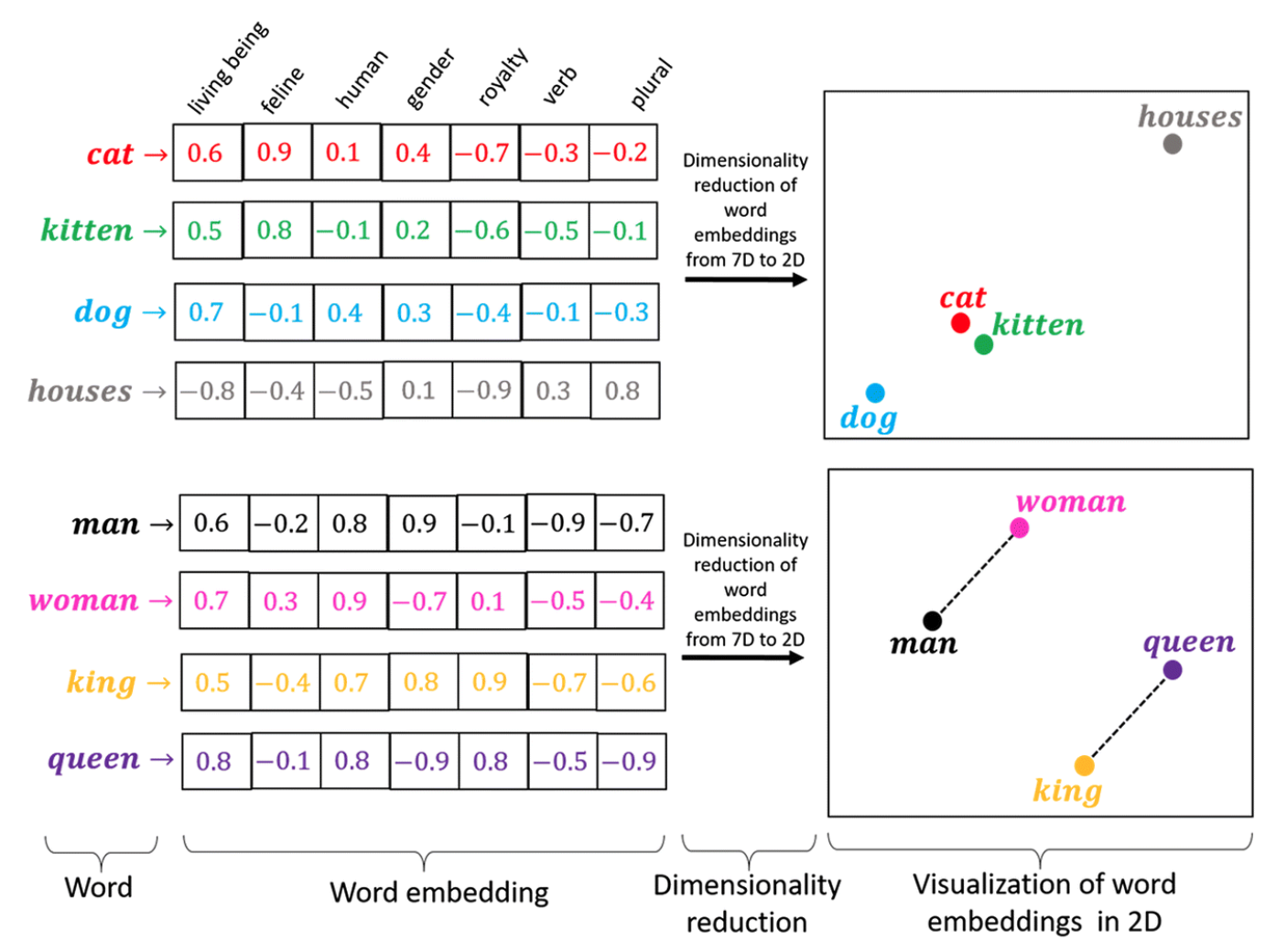
cat and kitten have more similar embeddings than cat and houses
We can use vector stores, such as Pinecone, to leverage the properties of embeddings in a scalable and performant manner. Vector stores are databases that store embeddings along with their metadata. To build a semantic search index, we need to embed all of the data that we want to search over and upload it to the vector store. After uploading the embeddings, we can embed any query and compare it with the existing embeddings in the vector store to find the K-nearest neighbors.
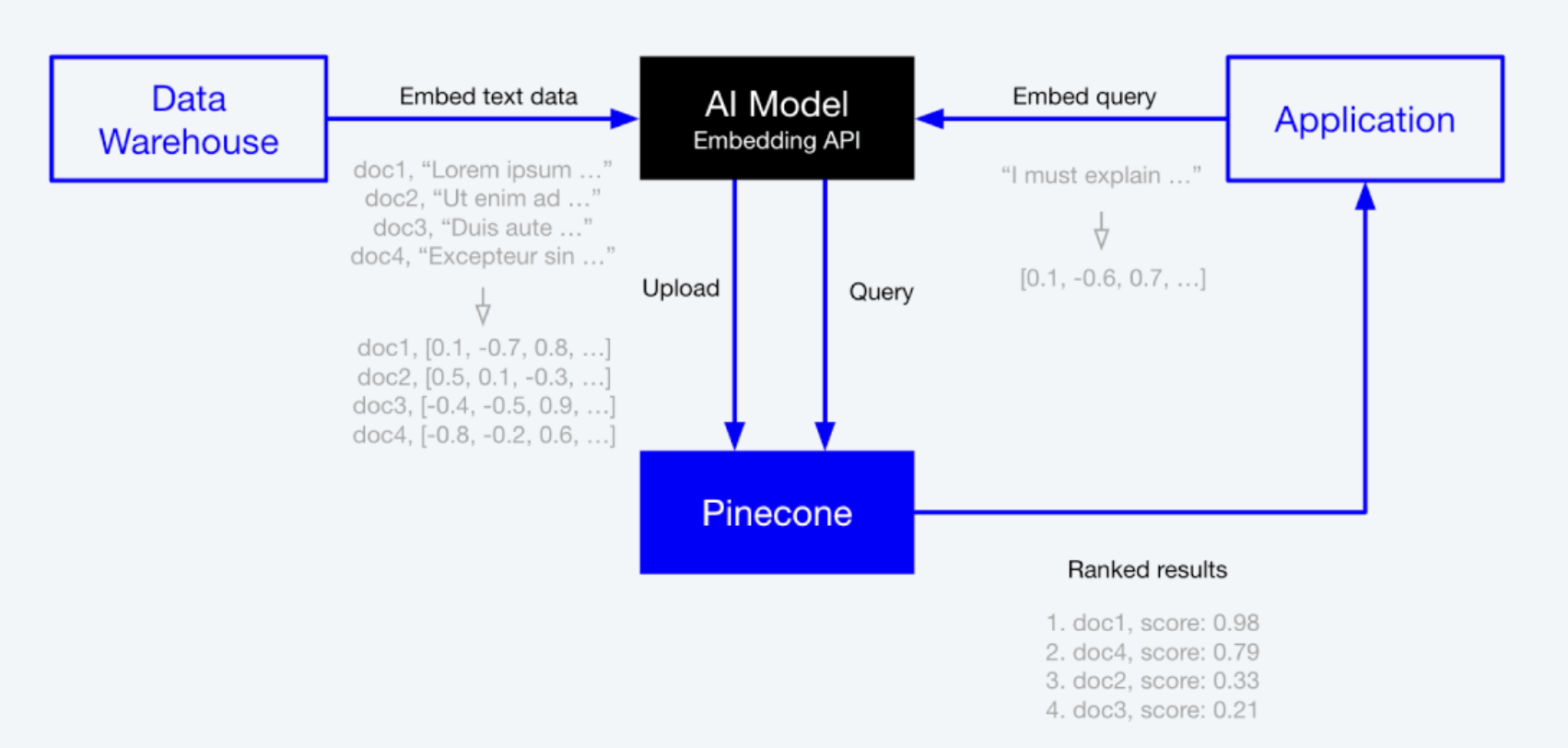
Scoped Search
One of the biggest limitations of LLMs is their inability to process large amounts of text. To overcome this limitation, we can use scoped search to find the most relevant piece of context for the user's input. This context can then be provided to the LLM to generate a much better response. To find this relevant piece of context, we can perform a semantic search over our context space. For example, when answering questions about our user manual, we can split the manual into chunks and embed each chunk. Then, we can embed a user's query and run a semantic search over our embedded chunks to find the chunk that most relates to the user's question. Once we have this, we feed this chunk along with the question into the LLM to generate an answer.
LangChain
It is possible to create LLM tools using OpenAI's text completion API. However, it is much more effective to use a library like LangChain, which provides an easy interface for LLM input/output and abstractions such as prompts, models, memory, and agents. These abstractions can be combined to create robust LLM applications.
Chains
The basic building block of LangChain are chains. As the name suggests, chains take in a set of inputs and generate a set of outputs. Chains can be composed and chained together to form larger chains with more complex functionality. Out of the box, LangChain provides built-in chains, but we can also implement our own custom chains to suit our needs.
Here’s an example of how to use chains to create a larger chain to demonstrate how easy to implement and useful they are. Let’s create a chain that can respond to an email asking a question about how to use our website. Assume we have a user manual that we can search over when given a question. Then here are the steps:
- Distill the email into a single question
- Find the answer in the user manual
- Using the answer we found, compose an email
Given these steps, we can then begin to write code to create a chain for each step. The first chain takes in an input variable "conversation" and outputs its response as the output key "query".
.png)
This is then fed into the UserManualSearchChain, which is defined as follows:
.png)
The inner workings of this chain are not important; all it does is search the user manual for the answer. Chains provide an abstraction layer because there's no need to understand what occurs in the chain, just the input and the output (similar to a function).
Note that the output key of the previous chain and the input key of the current chain must match. Unfortunately, the output of this chain does not fit exactly into our next chain, which actually writes the email. This is where we can use TransformChain, a chain provided by LangChain. By providing a transform function, we can turn the output of any chain into any shape we need. In our case, we use a function called parse_user_manual_response to turn the search response into usable context for our email drafting.
.png)
Finally, we have our chain that actually drafts the email given the “conversation” and “context”. Unlike the previous chains, this chain takes in two inputs.
.png)
We now have all the chains we need and we can combine them into one SequentialChain to have one clean chain that turns our user’s email into a response email with the answer:
.png)
LLM I/O
LLMs typically process natural language input and output. However, in a production application, we often need to use LLM reasoning capabilities to produce structured data. To solve this problem, LangChain's Prompt class provides an interface that injects instructions into your prompt, guiding the LLM to write in a specific format.
To get the desired output from LLMs, we sometimes need to provide additional context. Prompts can be used to achieve this. LangChain provides an easy way to deal with prompts and instruct the LLM to structure the output as JSON. We create a ResponseSchema object for each field we want the LLM to output. In this case, we have two ResponseSchema objects, "search_type" and "reasoning". LangChain will then convert these into formatting instructions for the LLM to format the output as a JSON with the two specified fields.
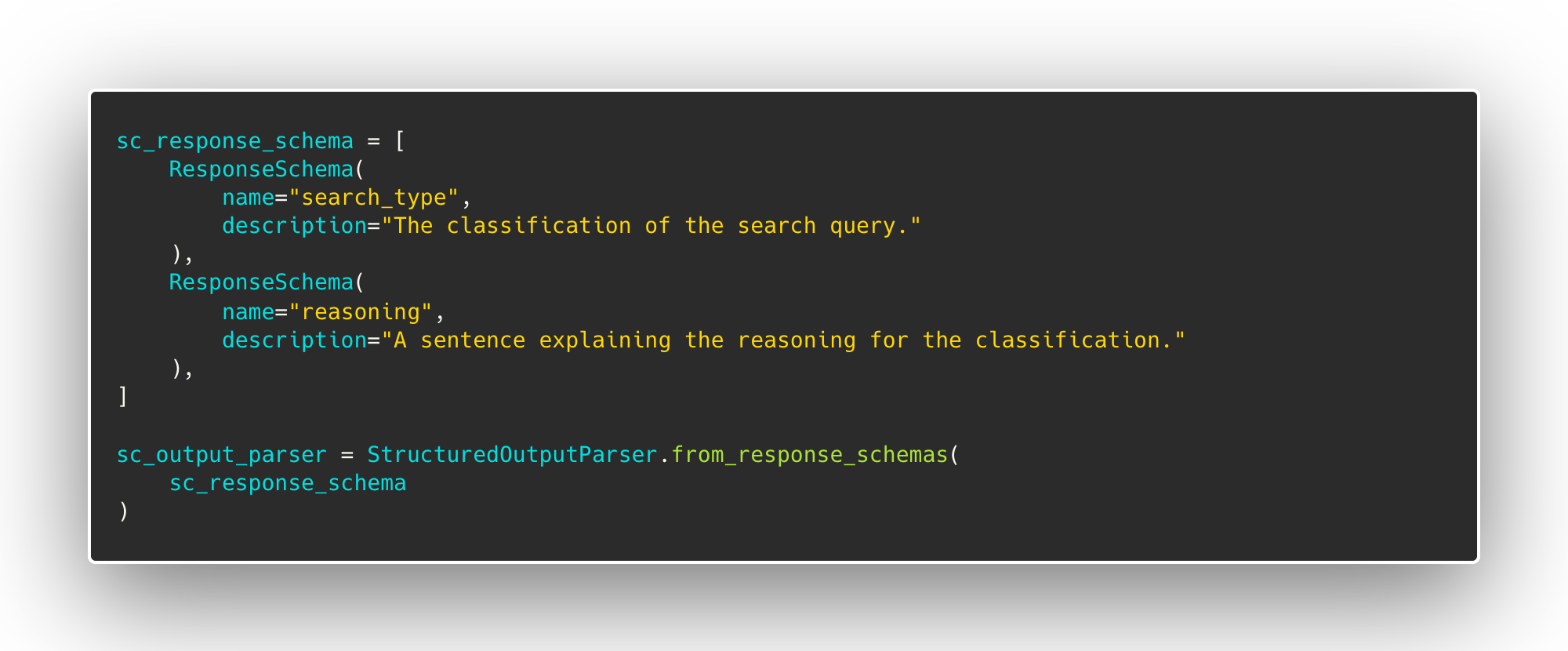
These can then be parsed out using LangChain’s StructuredOutputParser into a dictionary to use in Python code.
Agents
The bread and butter of our application are agents. These are conversational LLMs that can use tools to accomplish a variety of tasks, which, due to the limited context size of LLM’s, is a powerful way to have LLM’s be able to perform several tasks rather than just one well-defined task. A tool can be anything the agent can use to aid in its response to the user: a function LangChain’s Agent class is able to take in the input and calls the correct tool to provide the necessary information back to the user. For instance, if the user asks the agent to do a semantic search, it will select the semantic search tool. If, on the other hand, the user wants is asking a general question, the agent can pick the tool that answers questions.
With all that being said, however, agents are far from perfect. The biggest limitation to agents is that they are highly irregular and non-deterministic. The same input given multiple times could generate differing results each time. Agents also have a hard time distinguishing between tools at times, which is why prompt engineering is so crucial when providing a description of each tool to the agent.
Conclusion
To wrap up, we’ve shown how LangChain can be used to create conversational agents that can leverage the strengths of LLMs and vector stores like Pinecone to create powerful and scalable applications. Though this was just a high-level introduction, it’s clear that these tools provide great promise for a wide range of applications and we’re excited to see what the future holds.
Try Out Generative Biological Search Today
Generative Biological Search is now available on the Enable Medicine Platform! You can access it by signing up for an Enable Medicine account.
These features are all still experimental, and we’re working hard to improve and expand their capabilities. Beyond today’s launch, we’re planning even more improvements to our platform, from adding more general biological knowledge in search, to better ways to operate on our data and interact with images more dynamically, to easier ways to summarize analyses.
Help Us Build the Future of Research
Imagine having access to assistance throughout your entire workflow, guiding you not only with the process of research but providing necessary insight required. Ask it to summarize your data; to recommend next steps; to build plots and create insights from your findings; and to relate your findings to other studies. More than ever before, we believe we have the tools to chart a concrete roadmap toward this vision.
By continuing to innovate and adapt the latest in AI to science, we can help accelerate the entire field of biological research. On the Enable Medicine Platform, we hope users will be able to conduct novel biological research with increasing ease, increasing collaboration, and increasing support.
Our long-term vision hasn’t changed: a Biological Atlas to enable Biological Search and Open Research. We hope that developing our platform and Atlas will be a community-driven effort. Whether through AI and LLM expertise, or biological data and research, we are always looking for feedback and ideas, and even hope to build our own open source ecosystems. If you are a biologist, scientist, engineer, or anything in between, check out our website, get started with our platform, and reach out to us to collaborate on our vision for the future of science.






{kind=link}

